I have seen some posts that show how the duplicate detection works from an end user point of view and some that have described at high level what it does. My hope is to step you through setting up a duplicate detection rule and showing off the capabilities that Microsoft has put into this.
First off, there is now a new section under Settings called "Data Management." This section allows you to access:
 1. Duplicate Detection Settings
1. Duplicate Detection Settingsa. Specifies when duplicate detection should occur
2. Duplicate Detection Rules
a. Management of the actual rules that check for duplicates in the system
3. Bulk Record Deletion
a. Keep track of large deletions from the system
4. Data Maps
a. Create and Manage Data Maps for Imports
The Duplicate Detection Settings looks like this:
 This is great because you can choose whether or not you want to do duplicate checks only on a scheduled basis (to improve user performance), when users create or save records, when users come online, and/or during imports.
This is great because you can choose whether or not you want to do duplicate checks only on a scheduled basis (to improve user performance), when users create or save records, when users come online, and/or during imports.
Once you have that set, the next step is to actually set up the rule for which you check for duplicates. When you create a new duplicate detection rule you will see the following window (without everything being filled in):
 A few things to note here:
A few things to note here:
1. You can check for duplicates on the same entity OR different entities. So, if you have a fear of somone importing a bunch of names into leads that could exist in contacts or accounts, the system can be set up to check that for you.
2. You have the choice of making the rule "Case-sensitive" or not: 3. Notice that the criteria area is set up in a very similar fashion to Advanced Find. Allowing you to have as many rules as you want (to a limit of a matchcode length of 1000...I'll talk about that more later).
3. Notice that the criteria area is set up in a very similar fashion to Advanced Find. Allowing you to have as many rules as you want (to a limit of a matchcode length of 1000...I'll talk about that more later).
As you build out your criteria lines you have the options to check for: 1. Exact Match
1. Exact Match
2. Same First Characters
3. Same Last Characters
Below is a set of criteria that I set up to check against the email addresses checking for the first 10 characters on EmailAddress2 and the last 20 characters on EmailAddress3.
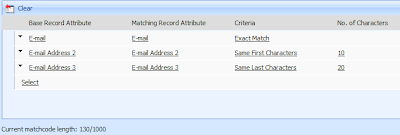
Note that there is a "Matchcode Length" maximum of 1000. What this means is that you can check up to 1000 characters, or data items in your duplicate check criteria. Let me give you some examples.
1. Nvarchar (textbox) with a maximum value of 100 are worth a matchcode length of 100. Meaning you could only check up to 10 textboxes that had a maximum length of 100. Even if the entire field is not used on a record it will still count as the maximum number allowed in the textbox.
2. Boolean (bit) take up 2 matchcode length values. 1 for true and 1 for false.
3. Picklist (dropdown) take up 255 matchcode length values.
From this you can see that you will have to mix and match a bit to get your rule just right but still make it under the 1000 matchcode limit. I'm sure it won't be a problem for most people but there will always be those who will hit this limit every time they create a duplicate detection rule.
The main reason that Microsoft has limited the amount of things you can check against is to make the rules manageable. The more complex the check the longer the check will take to run. Thus slowing down the user experience and making your scheduled checks take much longer.
Also, keep in mind that if you make multiple rules on the same entity you will be causing slowness to the system as well. I believe I was told that 4 or 5 rules per entity should be just fine but after that you will start to see a dip in performance. So, just be aware of that. I haven't tested this on a production server yet so I can't say one way or the other.
Once you have your rule set up you then publish the rule and it is applied to whatever your Duplicate Detection Settings are set to.
If you want to see a click through, Phillip Richardson has put up a screencast to show you what the actual check looks like. Here's the link: http://www.philiprichardson.org/blog/post/Titan-Duplicate-Detection.aspx
Great things coming. I'm real excited for CRM 4.0
David Fronk
Dynamic Methods Inc.
4 comments:
My installation has a limit of 450 characters per rule. Yours is 1000. How do I change mine to 1000?
J-Zar,
This post was actually from beta code. All of the installations that I have done with the RTM code only allows for 450 characters per rule. Microsoft probably brought that number down so as to not bog people's servers down with the new load it would create.
David Fronk
Dynamic Methods Inc.
Is there a way, supported or not, to increase the number of characters?
J. R. Halasz
J-Zar,
I haven't ever modified the matchcode length but I did find something that might work. This is 100% UNSUPPORTED so try this at your own risk. I found in the MSCRM_CONFIG.DeploymentProperties table there is a row with the ColumnName of "DupMatchcodeLength". You might be able to modify that to modify your maximum matchcode number. I don't know if it will work but that's the best place I found that might work.
David Fronk
Dynamic Methods Inc.
Post a Comment